

Qwen3-Coder-Next introduces ultra-sparse architecture for high-speed, repository-scale coding
Alibaba has released Qwen3-Coder-Next under the permissive Apache 2.0 license, allowing both enterprises and independent developers to use it commercially. The model weights are available on Hugging Face in four variants, along with a technical report detailing its training process and architectural innovations.
The launch comes amid a rapidly intensifying race to build the most capable coding assistant. In recent weeks, the space has seen major developments, including efficiency gains from Anthropic’s Claude Code ecosystem, OpenAI’s Codex app launch, and growing adoption of open-source frameworks like OpenClaw. Against this competitive backdrop, Alibaba is aiming to set a new benchmark for open-weight coding intelligence.
At its core, Qwen3-Coder-Next changes the economics of AI engineering. While the model contains 80 billion total parameters, it uses an ultra-sparse Mixture-of-Experts (MoE) architecture that activates only 3 billion parameters per forward pass. This enables reasoning performance comparable to large proprietary systems while maintaining the speed and cost profile of a lightweight model.
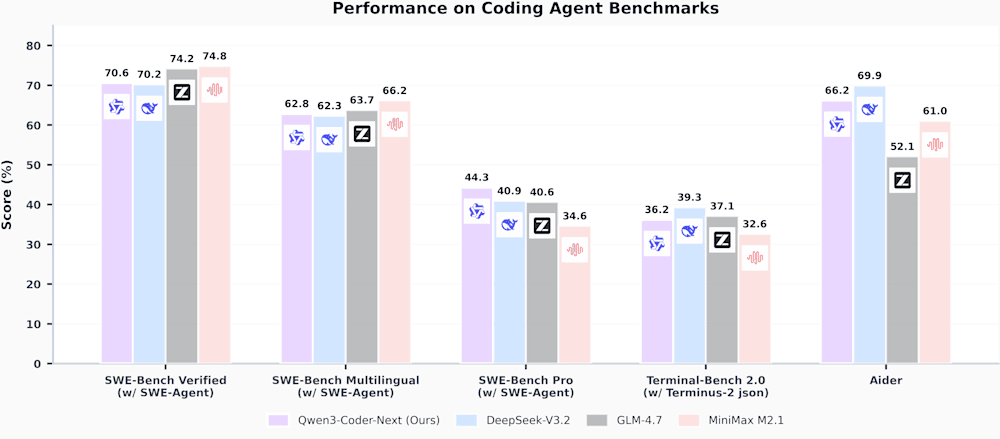
Qwen3-Coder-Next benchmarks. Credit: Alibaba Qwen
Solving the long-context bottleneck
The model’s key technical innovation is a hybrid architecture designed to overcome the quadratic scaling limitations of traditional Transformers.
With support for a massive 262,144-token context window, standard attention mechanisms would normally become prohibitively expensive. Traditional Transformers face a “memory wall,” where computation grows quadratically with sequence length.
Qwen addresses this by combining Gated DeltaNet with Gated Attention. Gated DeltaNet provides a linear-complexity alternative to softmax attention, allowing the model to maintain state across very long contexts without severe latency penalties.
When paired with the ultra-sparse MoE design, this setup delivers a theoretical 10× higher throughput on repository-level tasks compared to dense models of similar capacity. In practice, the agent can process an entire Python library or complex JavaScript framework at the speed of a 3B-parameter model, while retaining the structural understanding of an 80B system.
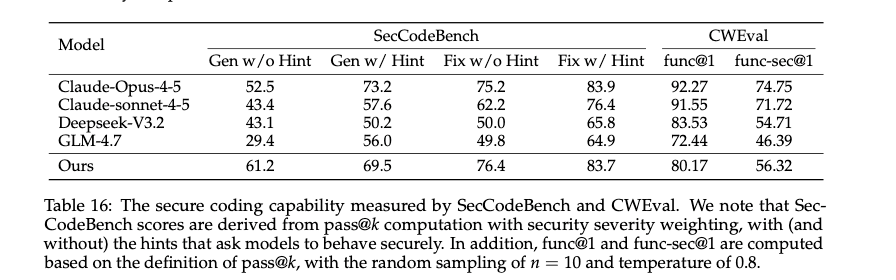
Qwen3-Coder-Next SecCodeBench benchmark results comparison table. Credit: Alibaba Qwen
To reduce hallucination during long-context training, the team used Best-Fit Packing (BFP), which preserves efficiency without the truncation issues of standard document concatenation.
An agent-first training pipelineThe
“Next” in the name reflects a major shift in training philosophy. Earlier coding models relied mostly on static code-text pairs. Qwen3-Coder-Next was trained using a large-scale agentic pipeline.
The team generated about 800,000 verifiable coding tasks, based on real bug-fixing scenarios extracted from GitHub pull requests and paired with fully executable environments.
Training was orchestrated through MegaFlow, a cloud-native system running on Alibaba Cloud Kubernetes. Each task followed a three-stage workflow: agent rollout, evaluation, and post-processing.
During rollout, the model interacted with a live container. If its code failed tests or crashed the environment, it received immediate feedback through reinforcement learning. This closed-loop setup allowed the model to learn from runtime outcomes and improve its debugging and recovery skills.

Image credit : qwen.ai
Key specifications:
• Support for 370 programming languages (up from 92 previously)
• XML-style tool calling with a qwen3_coder format for long code outputs
• About 600B tokens of repository-level training data for cross-file reasoning
Specialized expert models
A major differentiator in the training pipeline was the use of domain-specific expert models rather than a single generalist system.
The Web Development Expert focused on full-stack tasks such as UI construction and component composition. All samples were rendered in a Playwright-controlled Chromium environment, with React projects running on a Vite server to ensure correct dependencies. A vision-language model then evaluated the rendered output for layout quality.
The User Experience Expert was trained to maintain correct tool-call formats across different CLI and IDE environments like Cline and OpenCode. Training across diverse tool schemas improved robustness during real-world deployment.
After reaching peak performance, these expert models were distilled back into the final 80B/3B MoE system, allowing the lightweight deployment model to retain the knowledge of larger teacher systems.
Strong benchmarks and security awareness
The results are reflected in competitive benchmark performance. Using the SWE-Agent evaluation setup, Qwen3-Coder-Next achieved:
- 70.6% on SWE-Bench Verified, surpassing DeepSeek-V3.2 (70.2%).
- Close to GLM-4.7’s 74.2% score
In security-focused tests, the model also performed strongly. On SecCodeBench, it outperformed Claude-Opus-4.5 in code generation scenarios, scoring 61.2% versus 52.5%.
Notably, it maintained high scores even without explicit security hints, suggesting it learned to anticipate vulnerabilities during its 800,000-task agentic training process.
In multilingual security evaluations, it also outperformed DeepSeek-V3.2 and GLM-4.7 on the CWEval benchmark, achieving a func-sec@1 score of 56.32%.
A challenge to closed coding models
This release represents a major open-weight challenge to proprietary coding systems. By demonstrating that a model with only 3B active parameters can handle real-world software engineering tasks at the level of much larger systems, Alibaba is pushing agentic coding toward broader accessibility.
The key industry insight is that context length and throughput are more important than sheer parameter count. A model that can scan a 262k-token repository and verify its work in seconds is often more practical than a larger, slower, and more expensive alternative.
As the Qwen team notes, scaling agentic training rather than model size alone is the main driver of real-world coding agent capability. With Qwen3-Coder-Next, the era of massive monolithic coding models may give way to fast, sparse systems that combine deep reasoning with high execution speed.